通用文件导入(CSV) 连接器
这是本地连接器。
CSV 连接器会从 .CSV 文件中收集设备、业务单位或用户的数据。 在 .CSV 文件的第一行填入列标题,然后填写您想要导入的数据。 创建连接器时,应上传一个示例文件,以便连接器能够正确映射 .CSV 文件中的列。
选项
CSV 连接器具有以下选项:
- 连接器名称:连接器的名称。
- 连接器服务器名称:与此连接器关联的连接器服务器的名称。 每个连接器只能与一个连接器服务器关联。 如果将连接器添加到特定的连接器服务器,则此字段可能会自动填充。 或者,您可以从列表中选择连接器服务器。
- 路径:服务器上存储 .CSV 文件的目录。 请确保所有新文件都保存到同一个目录,连接器需要导入这些文件中的数据。 该路径必须是连接器服务器实用工具的本地路径。
- 文件名筛选器:如果只想收集特定命名约定的文件数据,您可以筛选目录中的 CSV 文件。 可以使用 * 作为通配符。 例如:*_data.csv
- 数据类型:选择要导入的数据类型。 如果要导入多种数据类型,请为每种数据应用不同的连接器。
- 分隔符:选择文件中用于分隔值的分隔符类型。
- 日期格式:选择文件中使用的日期格式。
- 时间格式:选择文件中使用的时间格式。
- 时区:选择文件中数据使用的时区。
- CSV 示例文件:上传一个示例文件,文件应包含第一行的列标题和至少一行数据,以便连接器能将各列映射到数据库中的值。 上传示例文件之前,您应选择数据类型。 利用示例文件,您能够将文件内的值映射到 Neurons 数据库中的值。
- 重复:连接器应该多久收集一次数据。
- 开始时间:连接器应该开始运行的时间。 为尽量减少对网络和应用程序的影响,我们通常建议选择在晚上或周末运行连接器。
- 活动:连接器是否处于活动状态。 连接器处于活动状态时将根据您创建的计划运行。 如果清除该复选框,连接器则会变为非活动状态,并且在您再次启用该复选框并保存连接器之前,不会再收集数据。
有关配置或使用连接器的详细信息,请参阅连接器。
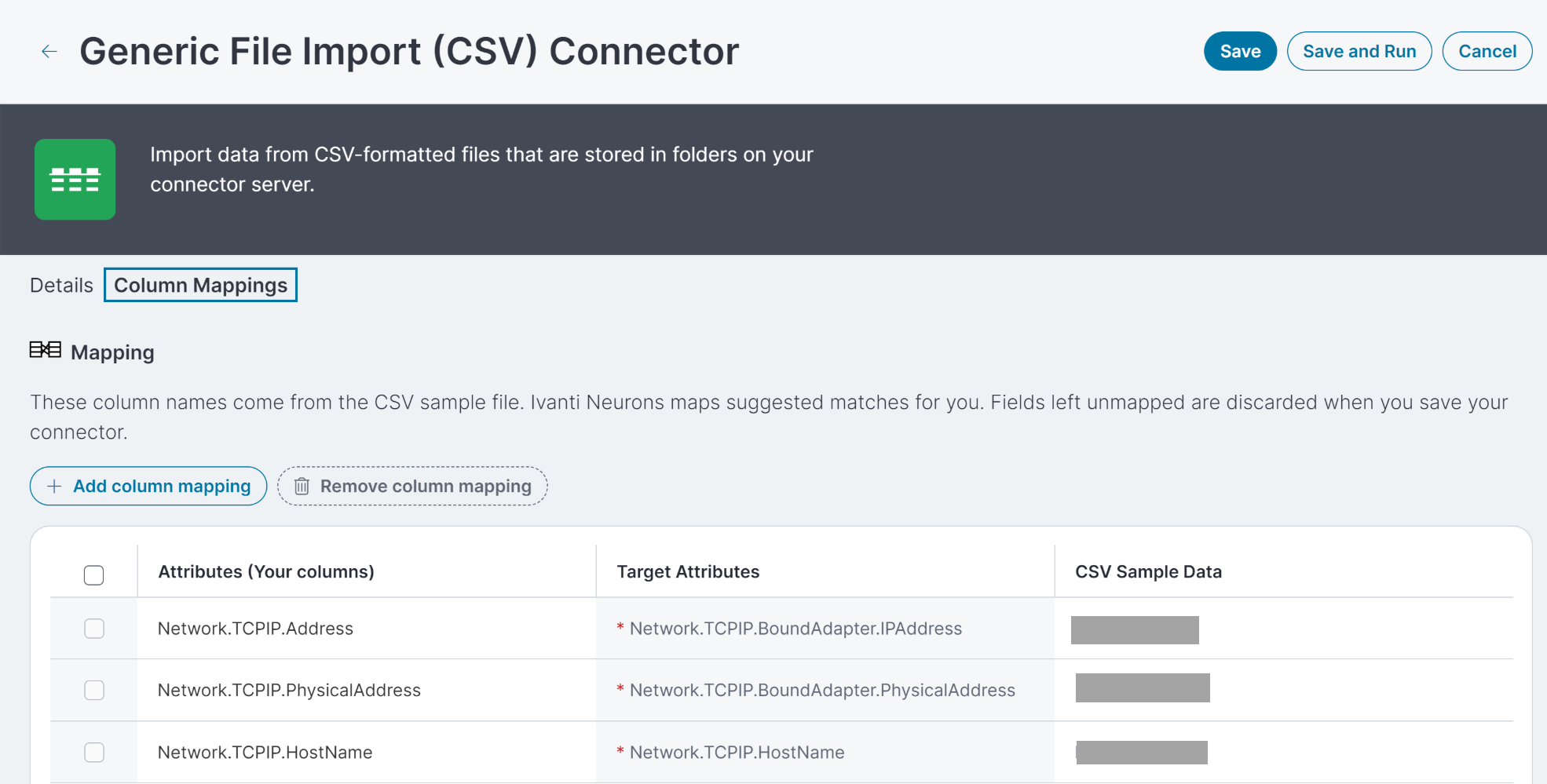
映射
上传示例文件并填写连接器的必填字段后,使用列映射选项卡将各列映射到数据库中的值。 Neurons 会为您映射建议匹配,但您仍应该查看建议,并进行必要的修改。
-
属性列显示您的示例文件列标题。
-
CSV 示例数据列显示一个示例文件中的示例值列。
-
目标属性列显示 Neurons 数据库中的值。 带有星号的“目标属性”将用于匹配设备并确保不存在重复记录,因此必须映射“目标属性”,以便保存和使用连接器。 举例来说,如果用户选择的数据类型是“设备”,则必需属性为 IP 地址(Neurons 中的 Network.TCPIP.Address)、物理(NIC 或 MAC)地址(Neurons 中的 Network.TCPIP.PhysicalAddress)和主机名(或完全限定域名/Neurons 中的 NetworkTCPIP.HostName)。
Neurons 根据协调规则导入数据并将其匹配到现有对象。 每个导入的对象必须具有足够的唯一识别信息,否则 Neurons 将忽略该对象。 对于设备来说,此信息是指 Network.TCPIP.BoundAdapter.IPAddress、Network.TCPIP.BoundAdapter.PhysicalAddress 和 Network.TCPIP.HostName 的组合。 因此,这三个是必填字段。如果数据集不包含这三个属性,那么 Neurons 可能会删除该数据。 不过,您可以使用目标属性 CSVID 提供来自 CSV 数据的唯一身份属性。
举例来说,如果数据的导出源包含设备 UUID 列,则可以将设备 UUID 映射到 CSVID 属性。 这样一来,Neurons 会认为任何映射到 CSVID 的内容本身便是唯一的,无需任何其他信息即可唯一地标识设备。 Ivanti 建议使用 CSVID,尤其是其他属性中的数据不完整时。 这种做法会让 Neurons 认为设备有足够的信息可以导入。
重要提示:在使用 CSV 连接器导入数据之前,您必须验证 CSV 源与其他连接器使用的源之间的数据完整性。 CSV 数据完整性也会随着时间的推移而降低,因此请确保在每次执行 CSV 导入操作时导入最新数据。 每次通过 CSV 连接器导入数据之前都必须执行检查和更新,否则数据质量会下降并导致环境中出现问题。
-
要将“属性”映射到“目标属性”,请在“目标属性”列中找到值,然后单击“属性”列中的行。 您可以单击空白表单元格来为示例文件选择列标题。
-
要将目标属性映射到属性,请在“属性”列中找到值,然后点击“目标属性”列中的行。 您可以单击空白表单元格,然后从出现在右侧的菜单中选择数据库值。
如果没有在第一次上传示例文件时映射字段,连接器会忽略该列中的数据。 如果想要在上传文件后映射字段,请单击添加列映射然后选择列标题。
此时无法创建自定义目标属性。
使用以下 Neurons 属性名称与 CSV 列名称建立映射:
属性名称

CSV 列名称

如需了解此连接器和其他连接器导入的默认属性,以及如何将属性映射到目标属性,请参阅连接器数据映射。