Autoscaling
Autoscaling is a license key controlled feature and is not available on all Traffic Manager variants. See the Ivanti Web site for details about supported configurations.
Introduction
The “application autoscaling” option monitors the performance of a service running on a supported virtual or cloud platform. When the performance falls outside the desired service level, the Traffic Manager can then initiate an autoscaling action, requesting that the platform deploys additional instances of the service. The Traffic Manager will automatically load balance traffic to the new instances as soon as they are available. The Autoscaling feature consists of a monitoring and decision engine, and a collection of driver scripts that interface with the relevant platform.
Autoscaling is a property of a pool. If enabled, you do not need to provide a specific list of nodes in the pool configuration. Instead, if performance starts to degrade, additional nodes can be requisitioned automatically to provide the extra capacity required. Conversely, a pool can be scaled back to free up additional nodes when they are not required. Hence this feature can be used to dynamically react to both short bursts of traffic or long-term increases in load.
A built-in service monitor is used to determine when a pool needs to be auto-scaled up or down. The service level (response time) delivered by a pool is monitored closely. If the response time falls outside the desired level, then Autoscaling will add or remove nodes from the pool to increase or reduce resource in order to meet the service level at the lowest cost.
How It Works
The autoscaling mechanism consists of a Decision Engine and a collection of platform-dependent Driver scripts.
The Decision Engine
This monitors the response time from the pool, and provides scale-up/scale-down thresholds. Other parameters control the minimum and maximum number of nodes in a pool, and the length of time the Traffic Manager will wait for the response time to stabilize once a scale-up or scale-down is completed.
For example, you may wish to maintain an SLA of 250ms. You can instruct the Traffic Manager to scale up (add nodes) if less than 50% of transactions are completed within this SLA, up to a maximum of 10 back-end nodes. Alternatively, it should scale-down (remove nodes) progressively to a minimum of 1 node if more than 95% of transactions are completed.
You can manually provision nodes by editing the max-nodes and min-nodes settings in the pool. If the Traffic Manager notices that there is a mismatch between the max/min and the actual number of nodes active, then it will initiate a series of scale-up or scale-down actions.
The Cloud API Driver
The Traffic Manager includes API driver scripts for Amazon EC2, Rackspace and VMware vSphere cloud environments. Before you can create an autoscaling pool, you must first create a set of cloud credentials pertaining to the cloud API you wish to use. These credentials contain the information required to allow a Traffic Manager to communicate with the aforementioned cloud providers. The precise credentials used will depend on the cloud provider that you specify. For details, see Cloud Credentials.
The decision engine initiates a scale-up or scale-down action by invoking the driver with the configured credentials and parameters. The driver instructs the virtualization layer to deploy or terminate a virtual machine. Once the action is complete, the driver returns the new list of nodes in the pool and the decision engine updates the pool configuration.
Example Timeline for an Autoscaling Event
The following diagram depicts the timeline of an autoscaling event in the Traffic Manager. At the point the "scale-up threshold" is breached, the hysteresis period begins to ensure that the condition persists and is not just a momentary spike. Should the performance of the pool return to the expected level during this period, the Traffic Manager then abandons the autoscaling event.
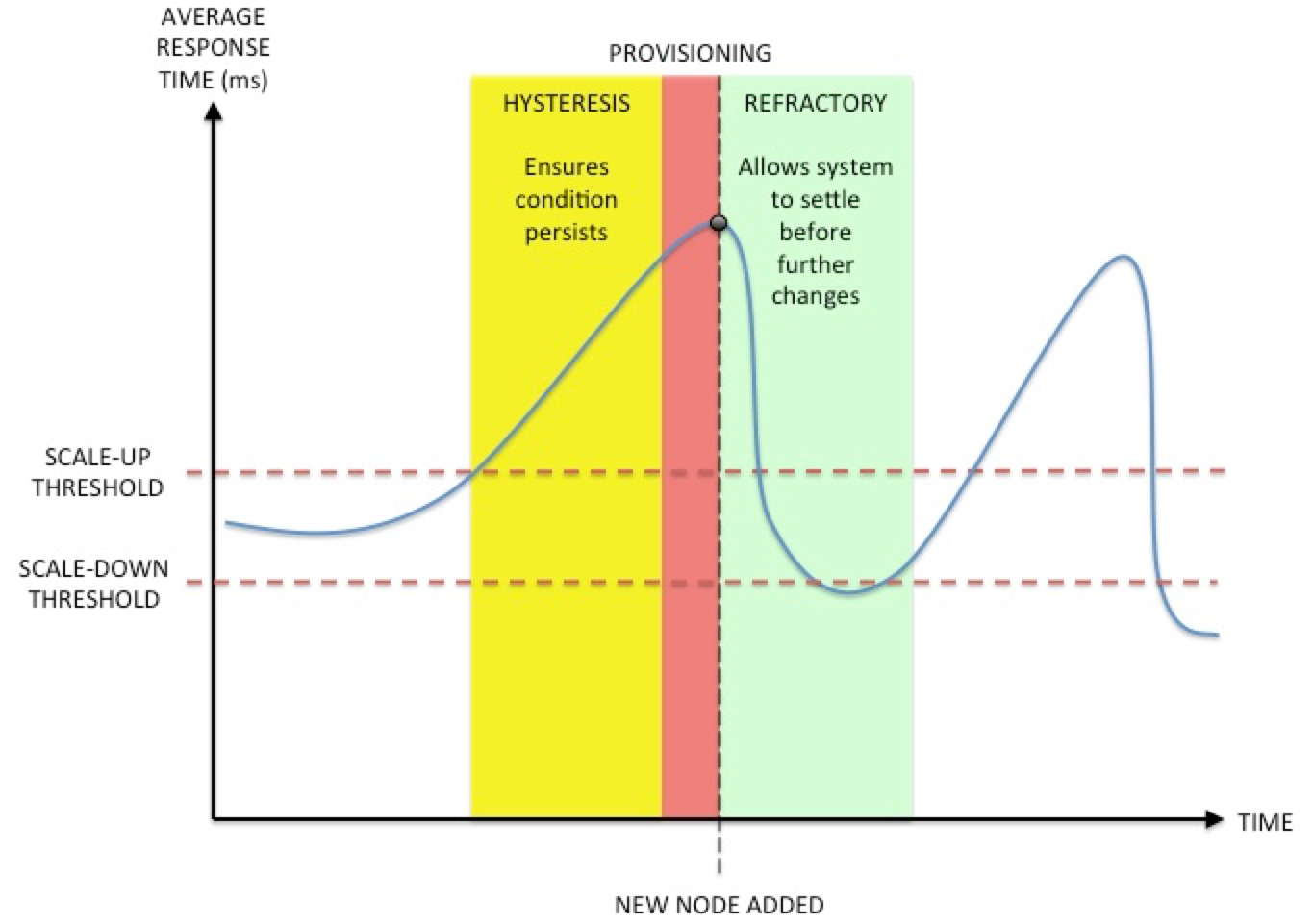
After the threshold breach has persisted for the length of the hysteresis period, the Traffic Manager's autoscaling mechanism triggers the creation (or deletion, if the diagram were to depict a scale-down event) of a new backend server node instance using the API of the chosen cloud or hypervisor. This process culminates in the successful creation of the node and its addition to the load-balancing pool.
With the addition of the new server node to the pool, the refractory period begins. During this period, the Traffic Manager ensures no further autoscaling events are triggered, and thus ensures that the performance of the service is able to settle to its new level before being re-assessed against the scaling thresholds.
To configure the thresholds and periods described here, see Configuring Autoscaling.
Configuring Autoscaling
The mechanism employed to implement autoscaling in a pool involves allowing the Traffic Manager to automatically make modifications to the pool configuration file (for example, to add or remove nodes as they are required). Where such a pool is in active use, there is a small possibility that this process of automatic updates could interfere with configuration changes made by the user through the Admin UI or Traffic Manager APIs, if they occur simultaneously. Therefore, Ivanti recommends that users double-check that their updates have taken effect by refreshing the pool page after making a change.
After you have created a set of credentials for your chosen cloud API, you can proceed to configure the autoscaling properties of your selected pool. For a new pool, use a pool type of Dynamic... and then select Ivanti vTM Autoscaler from the list of available options. For an existing pool, click Pools > Edit > Autoscaling to display the available configuration options:
Basic Settings
|
Setting |
Description |
|
autoscale!enabled |
Enables or disables Autoscaling. When this is enabled, nodes will be added and removed from the pool using the mechanism specified by autoscale!external. |
|
autoscale!external |
Some cloud providers have their own mechanism for performing autoscaling. In this case, a cloud provider would monitor the performance for a group of machines (those being the machines in the pool) and will add and remove machines as needed. The cloud provider will indicate to the Traffic Manager that it has added or removed a machine using its API. When the Traffic Manager has been informed of the change, it will add or remove nodes from the autoscaling pool accordingly. If you intend to use your cloud provider's autoscaling mechanism, set this parameter to “Yes”. If you intend to use the Traffic Manager's Autoscaling mechanism, set this to “No”. |
|
Cloud Credentials |
The set of credential required by a cloud's API. You can pre-configure sets of cloud credentials on the Catalogs > Cloud Credentials page. |
The Traffic Manager uses the API type of the credentials you specify here to present a set of configuration keys applicable to the requirements of the cloud provider:
Amazon EC2 Cloud Settings
|
Setting |
Description |
|
EC2 AMI |
The unique identifier of the virtual machine image from which you create new node instances. The Traffic Manager adds each newly created node to the pool when it identifies the need to increase capacity. A Traffic Manager seeing instances in the cloud using this AMI assumes that those instances belong to the corresponding pool. The unique identifier used here determines the operating system and the services running on the node. In an EC2 cloud, this parameter is called ImageId. |
|
EC2 Machine Type |
The identifier that indicates the size--in terms of resources--of the virtual machine required for an instance of a node that is to be added to a pool. In EC2, this parameter is called InstanceType. Typically, more powerful machines are associated with higher costs. |
|
Name Prefix |
An optional prefix added to the name of new nodes created during an autoscaling event. A Traffic Manager seeing instances in the cloud starting with this name assumes those instances belong to the corresponding pool. |
|
EC2 Security Group IDs |
A security group acts as a firewall that controls the traffic for one or more node instances. When an instance is launched, EC2 can associate it with one or more security groups. To create this association, specify a list of security group IDs (do not use group names) in the Extra Arguments text box. For EC2-Classic deployments, you must use security groups created specifically for EC2-Classic. Similarly, for EC2-VPC, you must use security groups created specifically for your VPC. If you do not specify security groups here, EC2 applies the default security group. |
|
EC2-VPC Subnet IDs |
A list of IDs of the VPC subnets where the new EC2-VPC instances are launched. Instances are evenly distributed among the subnets you specify in the Extra Arguments text box. To launch instances inside EC2-Classic, leave the list empty. To distribute auto-scaled EC2-VPC nodes evenly across different availability zones, Ivanti recommends listing the subnets present in different availability zones. |
|
Extra RunInstances Arguments |
A comma-separated list of key-value arguments for the AWS API function RunInstances, used at node creation time. Refer to the AWS documentation for RunInstances to see the list of available arguments. |
Rackspace Cloud Settings
|
Setting |
Description |
|
Image ID |
The unique internal identifier of the virtual machine image from which you create new node instances. The Traffic Manager adds each newly created node to the pool when it identifies the need to increase capacity. The unique identifier used here determines the operating system and the services running on the node. In a Rackspace cloud, this parameter is called imageId. You must use the internal image identifier here. To get a list of the image identifiers available for a given set of cloud credentials, run the included rackspace.pl script manually from the command line: $ZEUSHOME/zxtm/bin/rackspace.pl \ listimageids \ --cloudcreds=<credentials>
Replace <credentials> with your Rackspace cloud credentials. |
|
Flavor ID |
The internal identifier that indicates the size--in terms of resources--of the virtual machine required for an instance of a node that is to be added to a pool. In Rackspace, this parameter is called FlavorId. Typically, more powerful machines are associated with higher costs. To get a list of the size identifiers available for a given set of cloud credentials, run the included rackspace.pl script manually from the command line: $ZEUSHOME/zxtm/bin/rackspace.pl \ listsizeids \ --cloudcreds=<credentials>
Replace <credentials> with your Rackspace cloud credentials. |
|
Name Prefix |
The optional name prefix you can apply to each cloud-hosted virtual machine created by an autoscaling event. A Traffic Manager seeing instances in the cloud starting with this name assumes those instances belong to the corresponding pool. |
VMware vSphere settings
|
Setting |
Description |
|
VMware Template |
The built-in vSphere driver script creates new Virtual Machines (VMs) by deploying them from existing VM templates. These templates are pre-configured VMs which are marked as a template upon which new VMs can be based. The path of the template on a vCenter server is usually in the form: <DatacenterName>/vm/<TemplateName> |
|
Name Prefix |
New nodes will be created with this name prefix on the vCenter Server. If multiple pools are autoscaling on the same vSphere infrastructure, care must be taken to keep the name prefixes for each pool unique. |
|
Data Center |
All ESX hosts managed by the vCenter server are arranged in logical datacenters. Autoscaling is performed on the hosts or clusters contained within this datacenter. |
|
Data Store |
The data-store that will be used by the newly created virtual machines. If left blank, the default data-store used by the datacenter will be used (depending on the vCenter configuration). If a data-store is specified here, you should ensure the VM template uses the same data-store. |
|
VMware ESX Cluster |
The infrastructure on a vCenter server usually has a datacenter at the top level, which contains ESX hosts or a cluster of ESX hosts. If a cluster is configured with Dynamic Resource Scheduling (DRS), vCenter decides the hosts upon which new virtual machines will be placed. If no cluster is configured, this setting should contain the ESX hostname or IP where the new VMs are to be created. |
Node Settings
|
Setting |
Description |
|
autoscale!ipstouse |
(IP addresses-to-use) Instances in cloud environments typically have at least two IP addresses: one on a private network for communication with other nodes in the same cloud, and one on a public network for communication with the Internet in general. Select "private" or "public" to define whether traffic should be sent to the new node's private address, or its public address. Instances inside Amazon EC2-VPC do not have a public IP address by default. Select "public" to assign one at creation time. |
|
autoscale!port |
This defines the port to use when adding nodes to the pool. This port corresponds to the service listening on the back-end machine that gets spawned in the cloud environment. |
|
autoscale!min_nodes |
This defines the minimum number of nodes that are allowed to exist in the autoscaling pool. Note that this number will also include nodes that are currently marked as failed. A node failure in these circumstances can lead to a degradation in response times, which in turn will result in a new node being auto-scaled in. This behavior is not guaranteed, however. An autoscaling pool that contains failed nodes will not auto-scale beyond the number specified by autoscale!max_nodes. |
|
autoscale!max_nodes |
This defines the maximum number of nodes that are allowed to exist in the autoscaling pool. This ensures that a pool cannot auto-scale to an enormous number by itself. |
Scaling parameters
|
Setting |
Description |
|
autoscale!response_time |
The Traffic Manager monitors the response times (in milliseconds) of the nodes in an autoscaling pool. This is measured from the time the Traffic Manager starts initiating a connection to the node until it receives the first byte of the response. A response time of less than autoscale!response_time is considered conforming and longer times are considered non-conforming. The Traffic Manager continuously measures the percentage of conforming connections. |
|
autoscale!scaledown_level |
When the percentage of conforming responses rises above this value for at least autoscale!hysteresis seconds, the pool is scaled down (in other words, a node is removed from the pool). |
|
autoscale!scaleup_level |
When the percentage of conforming responses falls below this value for at least autoscale!hysteresis seconds, the pool is scaled up (in other words, a node is added to the pool). |
|
autoscale!refractory |
After a change to the pool size has been made (be it an increase or a decrease), the Traffic Manager will wait autoscale!refractory seconds before making another change. It will take some time for the new node to have its effect on the overall response times of the pool. So to prevent too many nodes from being created (or destroyed) at a time, you may want to increase this time period. |
|
autoscale!hysteresis |
The amount of time (in seconds) that an autoscaling condition must exist before the Traffic Manager instigates a change. This corresponds to (for example) the time that the pool's percentage of conforming connections must remain below autoscale!scaleup_level before a scale-up event occurs. |
|
autoscale!lastnode_idletime |
The time (in seconds) for which the last node in an auto-scaled pool must have been idle before it is destroyed. This is only relevant if autoscale!min_nodes is set to 0. |