Introducing the Virtual Traffic Manager
The Virtual Traffic Manager product family provides high-availability, application-centric traffic management and load balancing solutions in a range of software, appliance-ready, virtual appliance, and cloud-compute product variants. They provide control, intelligence, security and resilience for all your application traffic.
The Virtual Traffic Manager is intended for organizations hosting valuable business-critical services, such as TCP and UDP-based services like HTTP (Web) and media delivery, and XML-based services such as Web Services.
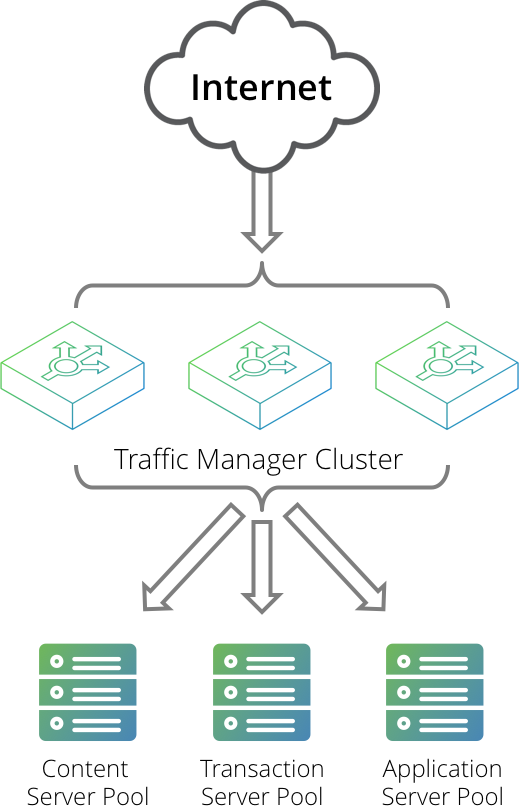
The Virtual Traffic Manager’s unique process architecture ensures it can handle large volumes of network traffic efficiently. Its inherent scalability allows you to add more front-end Virtual Traffic Manager or back-end servers to your cluster as the need arises. The cluster size is unlimited, and the performance of the Virtual Traffic Manager grows in line with the performance of the platform used.
The Virtual Traffic Manager represents a family of highly capable solutions that can be adapted and extended as new requirements arise. Using the unique TrafficScript language and built-in Java Extensions you can write sophisticated, tailored traffic management rules to inspect, transform, manage and route requests and responses. TrafficScript rules can manage connections in any TCP or UDP-based protocol.
Virtual Traffic Manager products are secure out-of-the-box, and are hardened against intrusion and Denial-of-Service (DoS) attacks. They incorporate the fastest and strongest 1 (SSL) encryption technologies, and can efficiently decrypt and re-encrypt large numbers of secure connections. TrafficScript rules, security policies and other content-based calculations can be applied to encrypted requests while retaining full end-to-end security.
For critical, high-availability solutions, the Virtual Traffic Manager offers cluster redundancy. This allows you to have unlimited numbers of active and passive standby front-end servers. If one of your active machines fails, a standby server is automatically brought into action; in the case of subsequent failure, more standby servers are available to take up the load. This ensures that there is no single point of failure in the system.
Typical Deployment