汎用ファイル インポート (CSV) コネクタ
これはオンプレミス コネクタです。
CSV コネクタは、デバイス、事業単位、またはユーザに関するデータを .CSV ファイルから収集します。 .CSV ファイルの最初の行の列見出しを使用して、インポートするデータを入力します。 .CSV ファイルの列を正しくマッピングできるように、コネクタの作成時にサンプル ファイルをアップロードしてください。
オプション
CSV コネクタには次のオプションがあります。
- コネクタ名: コネクタの名前。
- コネクタ サーバ名: このコネクタが関連付けられているコネクタ サーバの名前。 各コネクタは、1つのコネクタ サーバにのみ関連付けることができます。 コネクタを特定のコネクタ サーバに追加した場合は、このフィールドが自動的に入力されることがあります。 そうでない場合、リストからコネクタ サーバを選択できます。
- パス: サーバの上の、.CSV ファイルが保存されるディレクトリ。 各新しいファイルが同じディレクトリに保存され、コネクタがその場所からデータをインポートすることを確認してください。 このパスはコネクタ サーバ ユーティリティのローカル パスでなければなりません。
- ファイル名フィルタ: 特定の命名規約を持つファイルからのみデータを収集する場合に、ディレクトリ内の .CSV ファイルをフィルタリングします。 ワイルドカード文字として * を使用します。 例: *_data.csv
- データ タイプ: インポートするデータの型を選択します。 複数のデータ型をインポートする場合は、各データ型で異なるコネクタを使用します。
- 区切り文字: 値を区切るためにファイルで使用する区切り文字のタイプを選択します。
- 日付形式: ファイルで使用される日付形式を選択します。
- 時刻形式: ファイルで使用される時刻形式を選択します。
- タイム ゾーン: ファイル内のデータに使用するタイム ゾーンを選択します。
- CSV サンプル ファイル: 最初の行に列見出しを入力し、1行以上にデータを入力したサンプル ファイルをアップロードして、列がデータベースの値にマッピングされるようにします。 サンプル ファイルをアップロードする前にデータ型を選択してください。 サンプル ファイルを使用すると、サンプル ファイルの値を Neurons データベースの値にマッピングできます。
- 繰り返し: コネクタがデータを収集する頻度。
- 開始時刻: コネクタが実行を開始する時刻。 ネットワークおよびアプリケーションへの影響を最小化するために、一般的に、夜間または週末にコネクタを実行することをお勧めします。
- アクティブ: コネクタがアクティブかどうか。 コネクタがアクティブな場合、作成したスケジュールに従って実行されます。 チェックボックスをオフにすると、コネクタが無効になり、チェックボックスをもう一度オンにして、データを保存するまで、データが収集されません。
コネクタの構成または使用の詳細については、「コネクタ」をご参照ください。
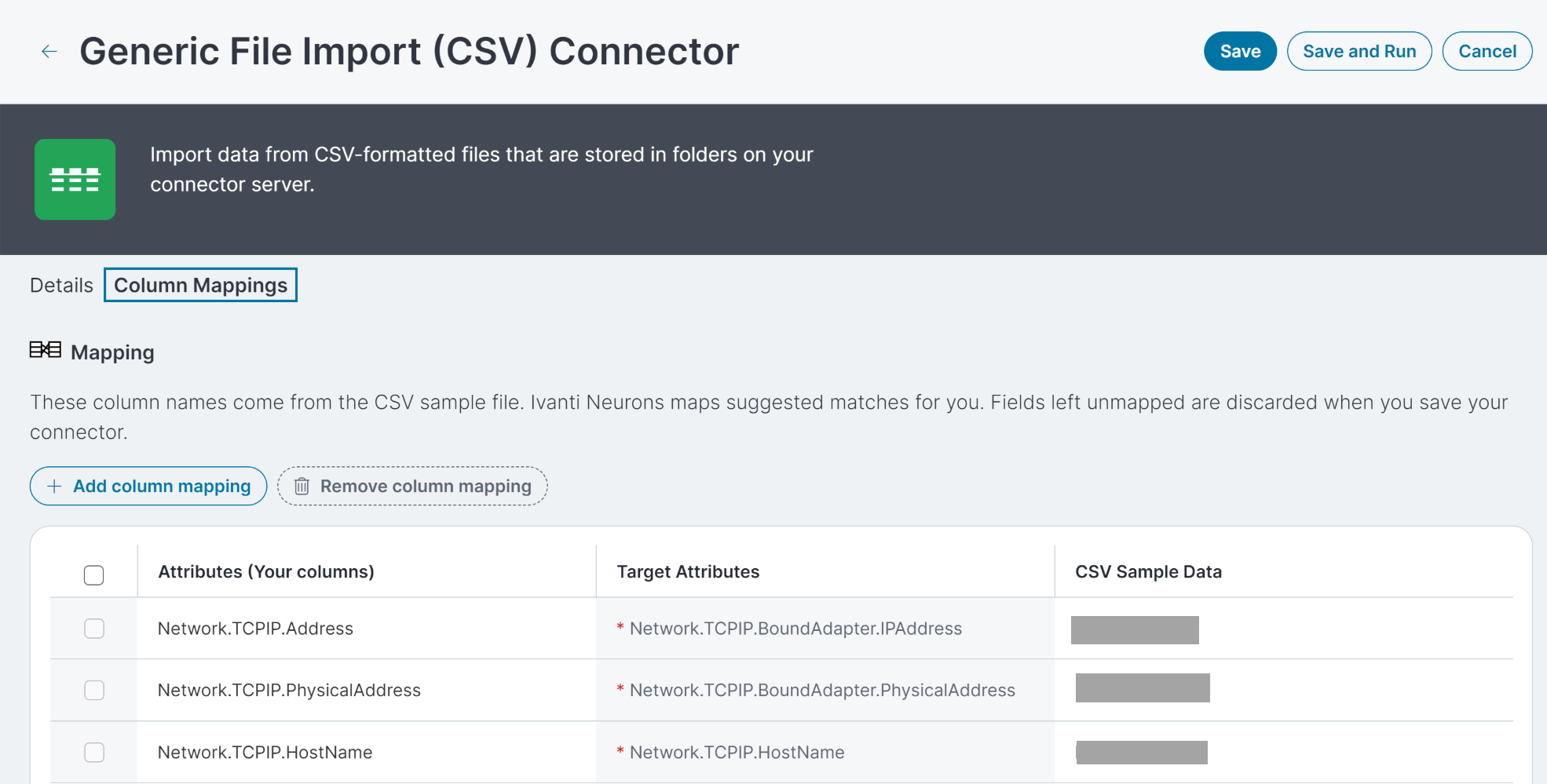
マッピング
サンプル ファイルをアップロードし、コネクタのすべての必須フィールドを入力した後、[列マッピング] タブを使用して、列をデータベースの値にマッピングします。 Neurons によって一致の候補が自動的にマッピングされますが、必ずそれらの候補を確認し、必要に応じて変更してください。
-
[属性] 列には、サンプル ファイルの列見出しが表示されます。
-
CSV サンプル データ列には、サンプル ファイルの列の値の例が示されます。
-
[ターゲットの属性] 列には、Neurons データベース内の値が表示されます。 アスタリスクが付いているターゲット属性はデバイスを照合し、重複するレコードがないことを確認するために使用されるため、コネクタを保存して使用するには、マッピングする必要があります。 たとえば、データ型としてデバイスを選択する場合、必要な属性は IP アドレス (Neurons での Network.TCPIP.Address)、物理 (NIC または MAC) アドレス (Neurons での Network.TCPIP.PhysicalAddress)、およびホスト (または完全修飾ドメイン名/Neurons での NetworkTCPIP.HostName) です。
Neurons はデータをインポートし、調整ルールに基づいて既存オブジェクトと突き合わせます。 インポートされた各オブジェクトには、オブジェクトを一意に識別できるだけの十分な情報があることが必要であり、そうでない場合、Neurons はそのオブジェクトを無視します。 デバイスの場合、この情報とは、Network.TCPIP.HostName、Network.TCPIP.BoundAdapter.IPAddress、Network.TCPIP.BoundAdapter.PhysicalAddress の組み合わせです。 だからこそ、これら3つのフィールドが必要なのです。時には、データセットにこれら3つの属性が含まれないことがあり、Neurons がそのデータを削除する場合があります。 ただし、ターゲット属性 CSVID を使用して、CSV データに由来する一意の ID 属性を入力できます。
たとえば、データ内に [デバイス UUID] 列があるソースからエクスポートする場合は、そのデバイス UUID を CSVID 属性にマップできます。 こうすることで、単独で CSVID にマップされているものはすべて一意であり、他のどの情報とも無関係に使用できることを Neurons に知らせることで、そのデバイスを一意に識別できます。 他の属性内のデータが完全でない場合には特に、CSVID を使用することをお勧めします。 こうすることで、インポートするにあたり十分な情報がそのデバイスにあることを Neurons に知らせます。
重要: CSV コネクタを使用してデータをインポートする前に、ご使用の CSV ソースと、他のコネクタが使用している CSV ソースの間の、データの整合性を検証する必要があります。 CSV データの整合性は経時的にも劣化しますので、CSV をインポートするたびに、最新のデータをインポートするようにしてください。 確認と更新は、CSV コネクタによる毎回のインポートの前に実行されなければなりません。そうでないと、劣化したデータ品質が環境内の問題の要因となります。
-
属性をターゲット属性にマッピングするには、[ターゲット属性] 列の値を見つけ、[属性] 列の行をクリックします。 空の表セルをクリックすると、サンプル ファイルから列見出しを選択できます。
-
ターゲット属性を任意の属性にマッピングするには、[属性] 列で値を見つけ、[ターゲットの属性] 列でその行をクリックします。 空の表セルをクリックすると、右側に表示されるメニューからデータベース値を選択できます。
初めてサンプル ファイルをアップロードするときにフィールドをマッピングしない場合は、コネクタがその列のデータを無視します。 後からフィールドをマッピングする場合は、[列マッピングの追加] をクリックして、列見出しを選択します。
現時点では、カスタムのターゲット属性を作成することはできません。
CSV 列名とマップするには、以下の Neurons 属性名を使用します。
属性名

CSV 列名

このコネクタおよび他のコネクタによってインポートされる既定の属性の概要と、属性がターゲット属性にどのようにマップされるかについては、「コネクタ データのマッピング」をご参照ください。