Working with Problems and Problem Management
•About the Problem Management Process
•Viewing the Problem Workspace
•Working with Problems and Problem Management
•About Creating a Custom Problem Status
•Working with the Problem Review Board
•Problem Business Object Reference
•Problem State Transitions Reference
About the Problem Management Process
A problem is defined as multiple incidents exhibiting common symptoms or a single incident with no known cause. The primary objective of problem management is to prevent incidents from happening and to minimize the impact of incidents that cannot be prevented. Proactive problem management analyzes incident records, and uses data collected by other Service Manager processes to identify trends or significant problems.
Sample Problem Process
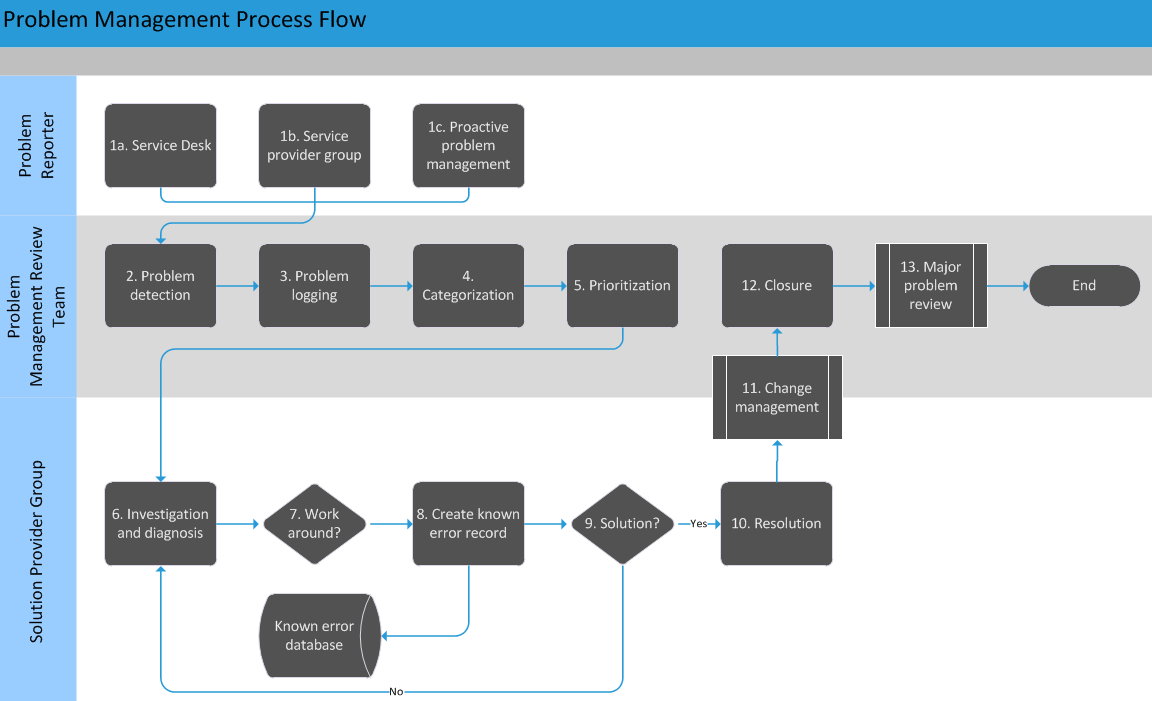
In proactive problem management, the Problem Manager routinely monitors logged incidents by category within a specific time frame to identify potential problems. Tracking and monitoring problems is a constant process of identifying and resolving problems and known errors.
•Problems: Interruptions in service identified by multiple incidents with the same symptoms or a single incident, and with unknown causes.
•Known errors: Problems for which the root causes have been identified and a workaround or a permanent fix has been identified, although the implementation of the permanent fix could be in the future.
The monitoring process includes trending, where the Problem Manager evaluates incidents and configuration items to identify problems by analyzing the following:
•Incident data for recurring incidents.
•Incident data for incidents that do not match existing problems.
•The IT infrastructure for problems that could lead to incidents.
Problems occur when:
•Incidents cannot be matched with known errors.
•Incidents recur over a time period.
About Problem Management
ITIL defines problem management as a process designed to eliminate recurring incidents from the IT infrastructure. A problem is identified by multiple incidents exhibiting common symptoms or a single incident with no known cause.
An incident is an unplanned interruption or potential interruption to service. A problem is the underlying root-cause of one or more incidents or potential incidents. Problems and incidents are distinct, and represent separate situations and activities. An incident becomes a problem when an incident has no workaround, or if there are recurring incidents affecting the same services or configuration items. A problem is identified after resolving one or more similar incidents.
Incidents where the root cause is unknown are identified as problems. When the root cause of such problems are identified, it might result in the resolution of the related incident and the problem becomes a known error. To implement a workaround or fix, problems might result in requests for change. The following diagram shows the relationship between the three IT processes:
Incident, Problem, Change Relationship

Problem management manages the lifecycle of all problems. The primary objectives of problem management are to prevent incidents from happening, and to minimize the impact of incidents that cannot be prevented. Proactive problem management analyzes incident records, and uses data collected by other Service Manager processes to identify trends or significant problems before they are logged as problems.
Incident management and problem management are closely linked. Problem management attempts to identify and resolve potential problems before they become incidents.
While incident management and problem management might seem similar, they have different goals. Incident management resolves an issue and restores services quickly; often by applying a workaround. Problem management identifies the root causes of incidents, determines a permanent resolution, and formulates a prevention plan.
The Service Manager application models the problem management sub process activities as defined by ITIL.
Notification or Problem Logging
This sub process consists of the initial logging of the problem. Logging the problem introduces the problem record into the system. The initial recording of a problem, including all relevant information that is available when the problem occurs, is part of this sub process.
Problems can be logged from incidents, or they might occur when implementing a change or release. The problem logging sub process also includes notifying the appropriate person or group that there is a problem and a need for assistance.
Problems can also be logged by the Problem Manager proactively monitoring incident trends or failures. For example, monitoring the default incident dashboards called All Incidents by Service or Active Incidents by Service this Year help the Problem Manager determine whether some of the service failure incidents are in fact due to a problem in the infrastructure.
Problem Determination or Investigation
When a problem is logged from another source, the Problem Manager or Problem Review Board determines whether the logged problem is in fact a problem. During the Investigation sub process, the Problem Manager might assign the problem to an owner and team, select members from the Problem Review Board to review the problem, search the Knowledge Base for solutions, create tasks for the problem, and so on.
Examples of a problem might be an outage, an incorrect or an unusual result. Problem investigation encompasses the collection, analysis, and correlation of data to determine and isolate the cause of the problem.
Problem Identification (Completion)
After the identification sub process, the problem is in active state. Problems might need to be correctly classified by their category and then prioritized by impact and urgency. See Default Priority Values.
Identification of configuration items or services as the root cause of the problem might be identified. The problem dashboard part called Active Problems with Linked CIs, for example, might help in this identification. During the problem identification period, tasks are created and assigned as steps to resolve the problem. A fix to the problem might require a resource or a vendor to work on the problem.
Problem Resolution
During the resolution sub process, the identification, implementation, and verification of the solution is carried through. A temporary resolution or workaround might be created and made available to solve current and future incidents arising from the problem. Notification is sent to the affected users and owners.
Proactive notifications to requesters and other stakeholders, escalations, and reporting can be done throughout the problem life cycle to make sure that the goals of successful problem resolution are being met.
Problem Managers can also view the cost of the problem while it is worked on, and get a final cost associated with the problem upon the problem's resolution or closure.
After problems are closed, they remain in the database and are viewable for reporting and analytical purposes. Problem Managers can view and generate dashboards and reports to view problem metrics and scorecard data.
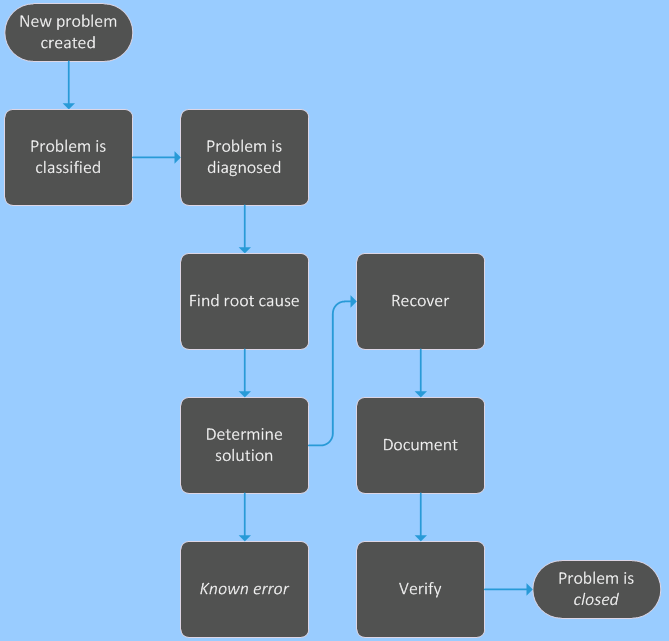
About the Problem Lifecycle
A typical problem detection, reporting, and recovery lifecycle is shown:
Problem Lifecycle
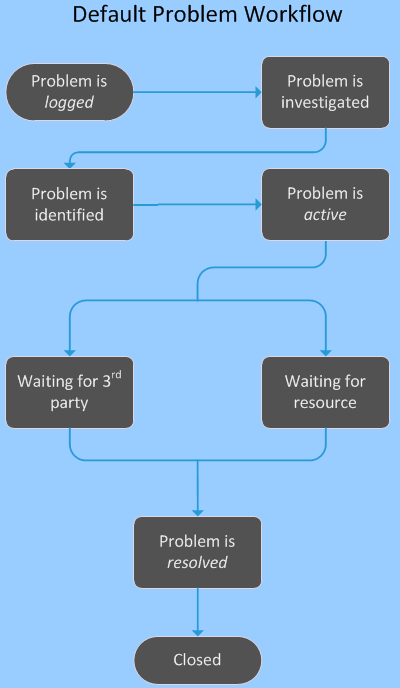
The default flow of a logged problem to its closed state is shown:
Default Problem Workflow
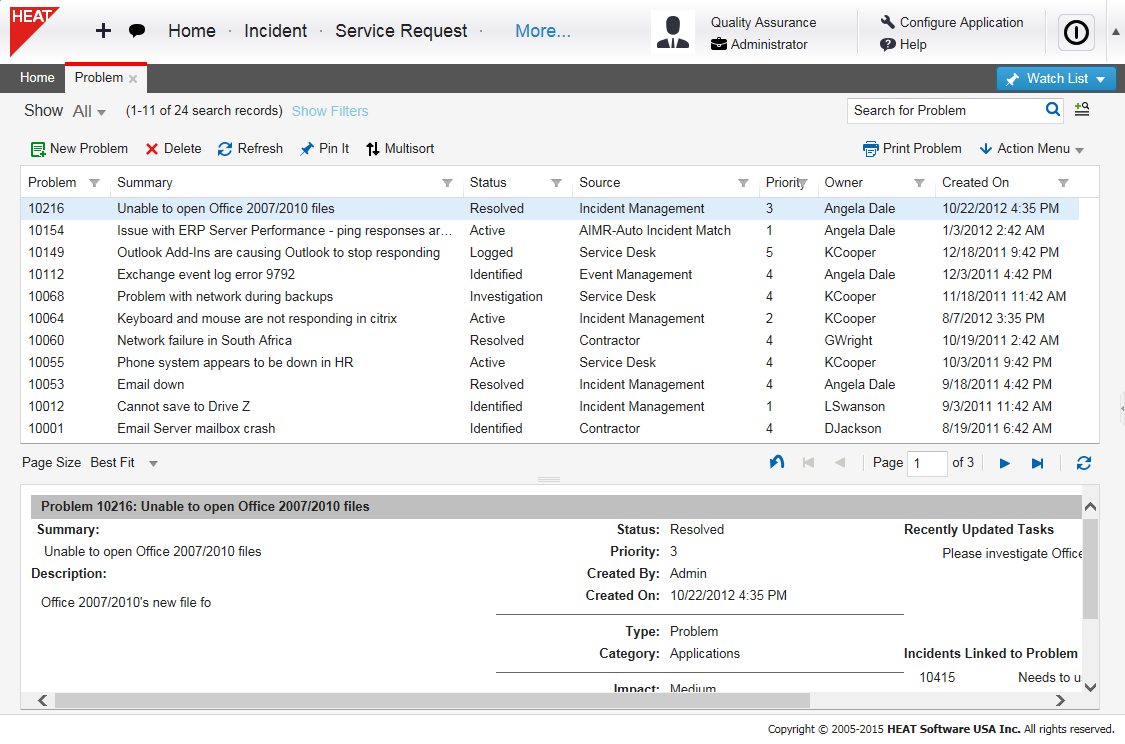
Viewing the Problem Workspace
1.Log into the Service Desk Console.
2.Open the Problem workspace. A list of all the problems, arranged from the highest problem ID appears.
The application of the data-segregation security organizational unit constraint to a role can affect the list of records that appear by default. If you do not see the default list of records in the search results list, you might need to select a different search from the saved searches menu.
3.Double-click a record to view details.
Problem Workspace