Connecteur d'importation de fichier générique (CSV)
Il s'agit d'un connecteur sur site.
Le connecteur CSV collecte des données sur les périphériques, les unités d'affaires ou les utilisateurs depuis des fichiers .CSV. Utilisez un en-tête de colonne comme première ligne du fichier .CSV, puis remplissez-le avec les données à importer. Lorsque vous créez le connecteur, vous devez télécharger vers le serveur un fichier échantillon, afin que les colonnes du fichier .CSV soit correctement mappées.
Options
Un connecteur CSV offre les options suivantes :
- Nom de connecteur : Nom pour le connecteur.
- Nom de serveur de connecteurs : Nom du serveur de connecteurs auquel ce connecteur est associé. Chaque connecteur ne peut être associé qu'à un seul serveur de connecteurs. Si vous avez ajouté le connecteur à un serveur de connecteurs spécifique, ce champ peut être rempli automatiquement. Sinon, vous pouvez sélectionner le serveur de connecteurs dans la liste.
- Chemin : Répertoire du serveur où sont stockés les fichiers .CSV. Vérifiez que tous les nouveaux fichiers sont stockés dans le même répertoire pour que le connecteur importe leurs données. Il doit s'agir d'un chemin local pour l'utilitaire de serveur de connecteurs.
- Filtre de nom de fichier : Filtre les fichiers .CSV dans le répertoire si vous souhaitez collecter uniquement les données des fichiers portant une convention de nom spécifique. Utilisez * comme caractère générique. Par exemple : *_data.csv.
- Type de données : Choisissez les types de données à importer. Pour importer plusieurs types de données, utilisez un connecteur différent pour chaque type.
- Délimiteur : Sélectionnez le type de délimiteur utilisé dans le fichier pour séparer les données.
- Format de date : Sélectionnez le format de date utilisé dans le fichier.
- Format d'heure : Sélectionnez le format d'heure utilisé dans le fichier.
- Fuseau horaire : Sélectionnez le fuseau horaire utilisé pour les données du fichier.
- Échantillon de fichier CSV : Téléchargez un fichier échantillon avec des en-têtes de colonne sur la première ligne et des données sur au moins une ligne, pour mapper les colonnes sur des valeurs dans la base de données. Vous devez choisir le type de données avant de télécharger un fichier échantillon. Le fichier échantillon vous permet de mapper les valeurs du fichier sur celles de la base de données Neurons.
- Répétitions : Fréquence à laquelle le connecteur doit collecter les données.
- Heure de début : Heure de la journée à laquelle le connecteur doit commencer à s'exécuter. Pour minimiser l'impact sur votre réseau et vos applications, nous vous recommandons d'exécuter en général les connecteurs la nuit ou le week-end.
- Actif : Indique si le connecteur est actif ou non. Lorsque le connecteur est actif, il s'exécute selon la planification que vous créez. Si vous désélectionnez la case à cocher, le connecteur est inactif et ne connecte aucune donnée tant que vous n'avez pas coché de nouveau la case et enregistré ce connecteur.
Pour en savoir plus sur la configuration ou l'utilisation des connecteurs, reportez-vous à « Connecteurs ».
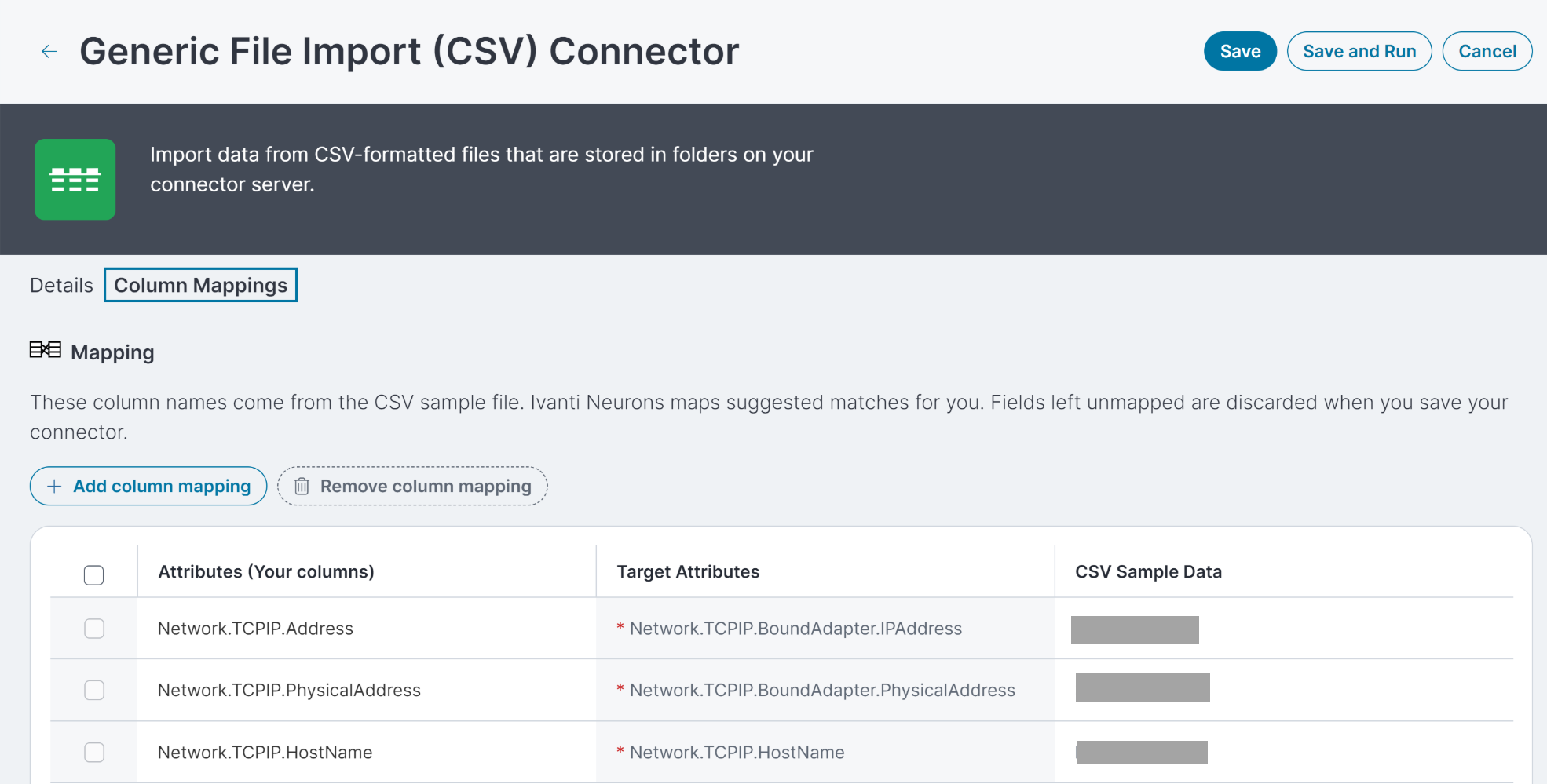
Mappage
Après avoir téléchargé un fichier échantillon vers le serveur et rempli tous les champs requis pour le connecteur, utilisez l'onglet Mappage de colonnes pour mapper les colonnes sur les valeurs de la base de données. Neurons mappe automatiquement les correspondances suggérées, mais vous devez passer ces suggestions en revue et y apporter des changements si nécessaire.
-
La colonne Attributs affiche les en-têtes de colonne de votre fichier échantillon.
-
La colonne Données CSV échantillon contient un exemple des valeurs de la colonne provenant du fichier échantillon.
-
La colonne Attributs cible affiche les valeurs de la base de données Neurons. Les attributs cible portant un astérisque servent à mettre les périphériques en correspondance et à garantir que vous n'avez pas d'enregistrement en double. Il faut donc les mapper pour enregistrer et utiliser le connecteur. Par exemple, si vous choisissez Périphérique sous Type de données, les attributs requis sont l'adresse IP (Network.TCPIP.Address in Neurons), l'adresse physique (NIC ou MAC) (Network.TCPIP.PhysicalAddress in Neurons) et le nom d'hôte (ou nom de domaine entièrement qualifié/NetworkTCPIP.HostName in Neurons).
Neurons importe des données et les fait correspondre à des objets existants en fonction de règles de rapprochement. Chaque objet importé doit posséder assez d'informations d'identification uniques. Sinon, Neurons l'ignore. Pour les périphériques, ces informations combinent les valeurs Network.TCPIP.BoundAdapter.IPAddress, Network.TCPIP.BoundAdapter.PhysicalAddress et Network.TCPIP.HostName (Adresse IP, adresse physique et nom d'hôte). C'est pourquoi ces trois champs sont obligatoires.Parfois, votre jeu de données n'inclut pas ces trois attributs et Neurons supprime les données. Cependant, vous pouvez fournir un attribut d'identité unique tiré des données CSV, à l'aide de l'attribut cible CSVID.
Par exemple, si vous exportez les données depuis une source incluant la colonne UUID de périphérique, vous pouvez mapper cet UUID de périphérique sur l'attribut CSVID. Cela indique à Neurons que toutes les valeurs mappées sur le CSVID sont uniques et peuvent être utilisées indépendamment de toute autre information pour identifier le périphérique de manière unique. Ivanti vous recommande d'utiliser le CSVID, surtout si vos données ne sont pas complètes dans d'autres attributs. Cela indique à Neurons que le périphérique dispose de suffisamment d'informations pour l'importation.
IMPORTANT : Avant d'importer des données avec le connecteur CSV, vous devez vérifier l'intégrité des données entre votre source CSV et les sources utilisées par les autres connecteurs. De plus, l'intégrité des données CSV se détériore au fil du temps, alors n'oubliez pas d'importer des données à jour à chaque importation CSV. Les vérifications et mises à jour doivent avoir lieu avant chaque importation avec le connecteur CSV. Sinon, la détérioration de la qualité des données provoque des problèmes dans votre environnement.
-
Pour mapper un attribut sur un attribut cible, repérez la valeur voulue dans la colonne Attributs cible, puis cliquez sur la ligne voulue dans la colonne Attributs. Lorsque vous cliquez sur la cellule de table vide, vous pouvez sélectionner un en-tête de colonne dans le fichier échantillon.
-
Pour mapper un attribut cible sur un autre, repérez la valeur voulue dans la colonne Attributs, puis cliquez sur la ligne voulue dans la colonne Attributs cible. Lorsque vous cliquez sur la cellule de table vide, vous pouvez sélectionner une valeur de base de données dans le menu qui s'affiche sur la droite.
Si l'un des champs n'est pas mappé lors du premier téléchargement du fichier échantillon, le connecteur ignore les données de la colonne correspondante. Si vous décidez ultérieurement de mapper ce champ, cliquez sur Ajouter un mappage de colonnes et sélectionnez l'en-tête de colonne voulu.
Pour le moment, il n'est pas possible de créer des attributs cible personnalisés.
Utilisez les noms d'attributs Neurons suivants pour les mapper sur les noms de colonne CSV :
Noms d'attribut

Noms de colonne CSV

Pour consulter une vue d'ensemble des attributs par défaut importés par ce connecteur et d'autres, et savoir comment les attributs sont mappés sur les attributs cible, reportez-vous à « Mappage des données de connecteur ».