Connettore importazione file generico (CSV)
Si tratta di un connettore in loco.
Il connettore CSV raccoglie i dati sui dispositivi, le business unit o gli utenti dai file .CSV. Utilizzare un'intestazione colonne per la prima riga nel file .CSV, quindi popolarlo con i dati che si desidera importare. È necessario caricare un file campione quando si crea il connettore per contribuire a mappare correttamente le colonne nel file .CSV.
Opzioni
Un connettore CSV presenta le seguenti opzioni:
- Nome connettore: un nome per il connettore.
- Nome server connettore: il nome del server connettore a cui è associato questo connettore. Ciascun connettore può essere associato a un unico server connettore. Se si è aggiunto il connettore a un server connettore specifico, questo campo potrebbe essere già popolato. Altrimenti, è possibile selezionare il server del connettore dall'elenco.
- Percorso: la directory sul server in cui vengono archiviati i file .CSV. Assicurarsi che ciascun nuovo file venga salvato nella stessa directory e che il connettore importi i dati da essi. Questo percorso deve essere locale per l'utilità server connettore.
- Filtro nome file: filtra i file .CSV nella directory se si desidera raccogliere i dati soltanto dai file con una convenzione di denominazione specifica. Utilizzare * come carattere jolly. Ad esempio *_data.csv
- Tipo dati: scegliere quali tipi di dati si desidera importare. Se si desidera importare più di un tipo di dati, utilizzare un connettore diverso per ciascun tipo di dati.
- Delimitatore: selezionare il tipo di delimitatore che il file utilizza per separare i valori.
- Formato data: selezionare il formato data utilizzato dal file.
- Formato ora: selezionare il formato ora utilizzato dal file.
- Fuso orario: selezionare il fuso orario utilizzato per i dati nel file.
- File campione CSV: caricare un file campione con le intestazioni colonna nella prima riga e dati in almeno una riga per contribuire a mappare le colonne in base ai valori nel database. È necessario selezionare il tipo di dati prima di caricare un file campione. Il file campione consente di mappare i valori nel file ai valori nel database Neurons.
- Ripetizioni: con che frequenza il connettore deve raccogliere i dati.
- Ora di inizio: l'ora del giorno in cui il connettore deve iniziare a funzionare. Per ridurre al minimo l'impatto sulla propria rete e sulle applicazioni, consigliamo di far funzionare generalmente i connettori di notte o nei fine settimana.
- Attivo: se il connettore è attivo o meno. Con il connettore attivo, il relativo funzionamento avviene in base al programma creato. Se si toglie il segno di spunta dalla casella di controllo, il connettore risulta inattivo e non raccoglierà dati fino a quando non verrà nuovamente selezionata la casella di controllo e salvato il connettore.
Per i dettagli sulla configurazione o sull'utilizzo di connettori, vedere Connettori.
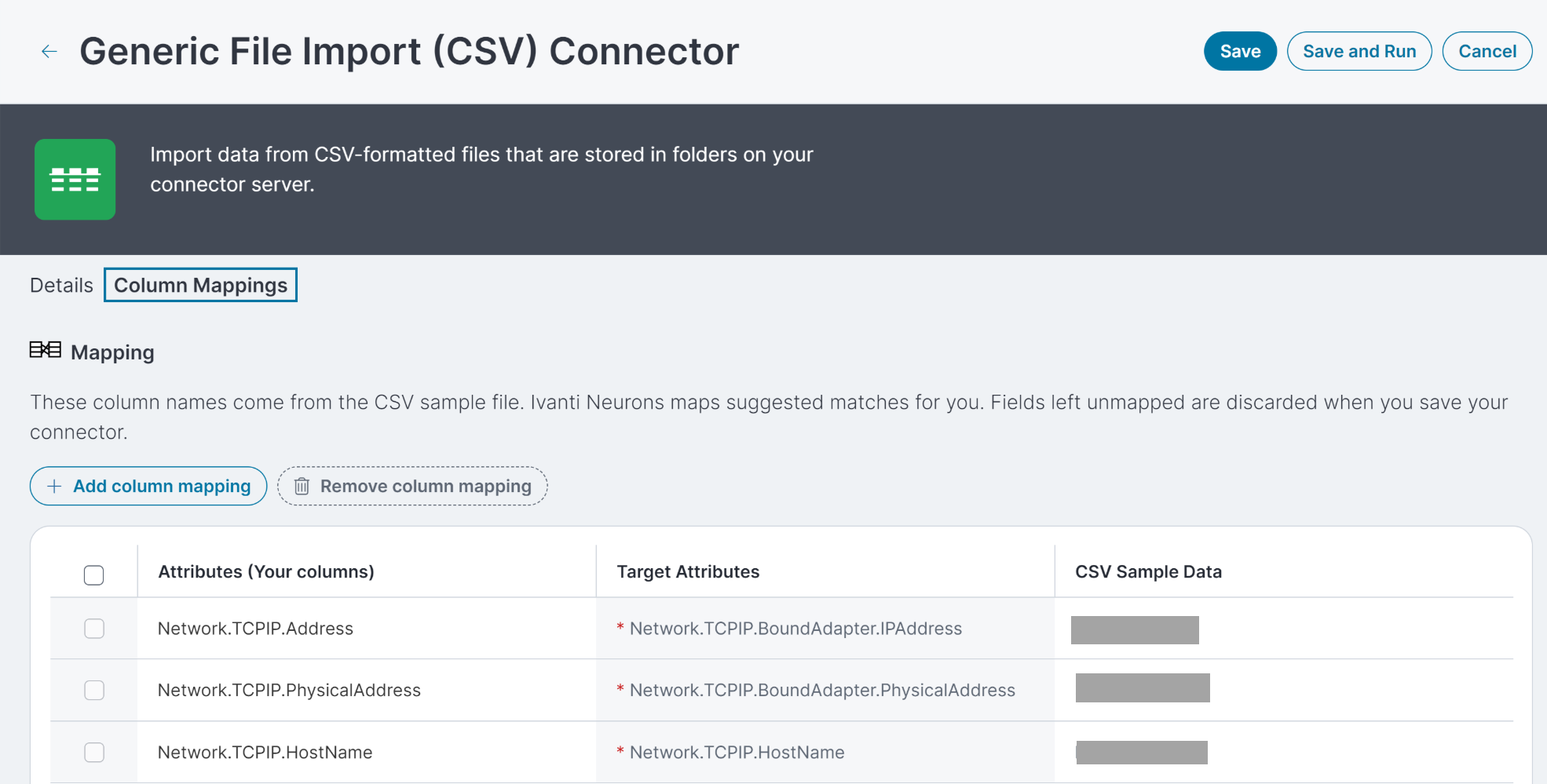
Mapping
Dopo aver caricato un file campione e completato tutti i campi richiesti per il connettore, utilizzare la scheda Mapping colonne per mappare le colonne ai valori nel database. Le mappe Neurons suggeriscono abbinamenti all'utente, ma si dovrebbero comunque esaminare tali suggerimenti ed effettuare modifiche solo se necessario.
-
La colonna Attributi mostra le intestazioni colonne nel proprio file campione.
-
La colonna Dati campione CSV mostra un esempio dei valori nella colonna dal file campione.
-
La colonna Attributi di destinazione mostra i valori nel database Neurons. Gli attributi target che presentano un asterisco vengono utilizzati per abbinare i dispositivi e assicurarsi di non avere record duplicati, pertanto devono essere mappati al fine di salvare e utilizzare il connettore. Ad esempio, se si sceglie Dispositivo come Tipo di dati, gli attributi richiesti sono l'indirizzo IP (Network.TCPIP.Address in Neurons), l'indirizzo fisico (NIC o MAC) (Network.TCPIP.PhysicalAddress in Neurons) e il nome host (o nome di dominio completamente qualificato/NetworkTCPIP.HostName in Neurons).
Neurons importa i dati e li abbina agli oggetti esistenti in base alle regole di riconciliazione. Ogni oggetto importato deve avere sufficienti informazioni di identificazione univoca, altrimenti Neurons lo ignorerà. Per i dispositivi, queste informazioni sono una combinazione di Network.TCPIP.BoundAdapter.IPAddress, Network.TCPIP.BoundAdapter.PhysicalAddress e Network.TCPIP.HostName. Pertanto, questi tre campi sono richiesti.A volte il set di dati non include questi tre attributi e Neurons può eliminare i dati. Tuttavia, è possibile fornire un attributo di identità univoco che proviene dai dati CSV, utilizzando l'attributo target di CSVID.
Ad esempio, se si esporta da un'origine che ha una colonna Device UUID nei dati, è possibile mappare il Device UUID sull'attributo CSVID. Questo indica a Neurons che qualsiasi cosa sia mappata sul CSVID è di per sé unica e può essere utilizzata indipendentemente da qualsiasi altra informazione per identificare in modo univoco il dispositivo. Ivanti consiglia vivamente di utilizzare il CSVID, soprattutto se i dati in altri attributi non sono completi. In questo modo Neurons sa che il dispositivo dispone di informazioni sufficienti da importare.
IMPORTANTE: prima di importare i dati utilizzando il connettore CSV, è necessario verificare l'integrità dei dati tra l'origine CSV e le origini utilizzate da altri connettori. Anche l'integrità dei dati CSV si deteriora nel tempo, quindi assicurarsi di importare dati aggiornati a ogni importazione CSV. I controlli e gli aggiornamenti devono essere eseguiti prima di ogni importazione dal connettore CSV, altrimenti il deterioramento della qualità dei dati causerà problemi nel proprio ambiente.
-
Per mappare un attributo in un attributo target, trovare il valore nella colonna Attributi target, quindi fare clic sulla riga nella colonna Attributi. Quando si fa clic sulla cella vuota della tabella, è possibile selezionare un'intestazione colonne dal file campione.
-
Per mappare un attributo target in un attributo, trovare il valore nella colonna Attributi, quindi fare clic sulla riga nella colonna Attributi target. Quando si fa clic sulla cella vuota della tabella, è possibile selezionare il valore database da un menu che appare sulla destra.
Se non si mappa un campo la prima volta in cui si carica il file campione, il connettore ignora i dati in tale colonna. Se si decide in un secondo momento che si desidera mappare un campo, fare clic su Aggiungi mapping colonne e selezionare l'intestazione della colonna.
Al momento non è possibile creare attributi di destinazione personalizzati.
Usare i seguenti nomi di attributi Neurons per mapparli con i nomi delle colonne CSV:
Nomi degli attributi

Nomi delle colonne CSV

Per una panoramica degli attributi predefiniti che vengono importati da questo connettore e da altri, e di come gli attributi vengono mappati agli attributi di destinazione, vedere Mapping dati connettore.